Notes: Horizontal table partitioning in PostgreSQL
In this blog, we cover basic PostgreSQL partitioning methods and theories around them

What is partitioning?
Table partitioning in SQL is the process of dividing large table data into smaller logically separated tables. Table partitioning helps to significantly improve database server performance as less number of rows have to be read, processed, and returned.
Benefits of partitioning
Partitioning can improve performance and maintainability. Let's have a look at these benefits.
Improved performance
By splitting the table, read and write performance is enhanced due to the below-mentioned reasons:
By specifying the search condition in SQL, the access range can be narrowed down to the specific partition(s) which reduces disk I/O and improves access performance.
The partitioned table can be placed in different tablespaces on physical disks. This distributes disk I/O, with reads and writes being performed in parallel on different physical disks, hence improving performance.
Improved maintainability
Since data now is added, updated, and deleted on partitions, we have better maintainability of data. For example, if we have sales data in month-wise partitions, and we want to keep only one year of data, we can create a new partition as the month changes and delete the old partition using DROP TABLE or TRUNCATE. Both can speed up the deletion processing and reduce the VACUUM load compared to the data deletion by DELETE.
Partition Methods
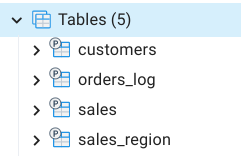
Tables involved in our examples:
Use this repo to start PostgreSQL and pgAdmin for trying out examples: https://github.com/khezen/compose-postgres
Range type partition
In a range-based partition, we divide data based on a range of values of the partition key column. It is logical to use these partitions where data is accessed with some range query like greater than, less than e.g. time-based data access.
-- range partition
CREATE TABLE sales (id int, user_id int, amount float, created_at date) PARTITION BY RANGE (created_at);
CREATE TABLE sales_2022_Jan PARTITION OF sales FOR VALUES FROM ('2022-01-01') TO ('2022-02-01'); -- last date is excluded in range
CREATE TABLE sales_2022_Feb PARTITION OF sales FOR VALUES FROM ('2022-02-01') TO ('2022-03-01');
CREATE TABLE sales_2022_Mar PARTITION OF sales FOR VALUES FROM ('2022-03-01') TO ('2022-04-01');
INSERT INTO sales VALUES (1, 201, 29.35, '2022-01-15');
INSERT INTO sales VALUES (2, 305, 5.25, '2022-02-28');
INSERT INTO sales VALUES (3, 111, 50.85, '2022-03-01');
INSERT INTO sales VALUES (4, 987, 62.40, '2022-01-01');
INSERT INTO sales VALUES (5, 201, 75.00, '2022-03-15');
SELECT * FROM sales;
SELECT * FROM sales_2022_jan;
SELECT * FROM sales WHERE created_at BETWEEN '2022-01-01' AND '2022-03-01';
UPDATE sales SET user_id = 201 WHERE id = 3;
SELECT * FROM sales WHERE created_at > '2022-02-01' AND user_id = 201;
SELECT * FROM sales_2022_mar;
-- default partition
CREATE TABLE sales_default PARTITION OF sales DEFAULT;
INSERT INTO sales VALUES (6, 987, 42.40, '2021-03-01');
INSERT INTO sales VALUES (7, 334, 98.25, '2022-05-11');
INSERT INTO sales VALUES (8, 125, 101.00, '2022-01-26');
SELECT * FROM sales;
SELECT * FROM sales_default;
Ref Image:

List type partition
In list-based partitioning, we divide data based on enum kind of data sets where we have fixed set values e.g. if we have orders table with field order_status which can take discreet values like initialized, payment_processing, success, failed and we have to access data based on these statuses frequently and data size is really huge. In this case, we can have a partition based on statuses. However, this might not be a good idea. It'd be better to use it in conjunction with time-based partition using subpartitioning. We'll cover that later in this blog.
In the below example, we are dividing our data based on countries and putting them into their respective continents partition.
-- list partition
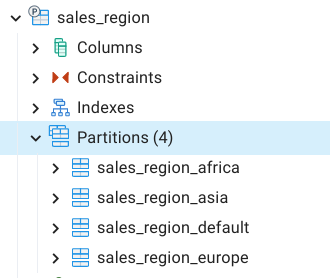
CREATE TABLE sales_region (id int, sales_id int, region text) PARTITION BY LIST (region);
CREATE TABLE sales_region_asia PARTITION OF sales_region FOR VALUES IN ('IN', 'SL', 'BD', 'PK');
CREATE TABLE sales_region_europe PARTITION OF sales_region FOR VALUES IN ('ES', 'UK', 'IT');
CREATE TABLE sales_region_africa PARTITION OF sales_region FOR VALUES IN ('KN', 'GH', 'SA');
INSERT INTO sales_region VALUES (1, 2, 'IN');
INSERT INTO sales_region VALUES (2, 1, 'UK');
INSERT INTO sales_region VALUES (3, 5, 'SL');
INSERT INTO sales_region VALUES (4, 3, 'SA');
INSERT INTO sales_region VALUES (5, 4, 'GH');
SELECT * FROM sales_region;
SELECT * FROM sales_region_africa;
SELECT * FROM sales_region WHERE region IN ('IN', 'SA');
UPDATE sales_region SET region = 'BD' WHERE id = '5';
SELECT * FROM sales_region_asia;
-- default partition
CREATE TABLE sales_region_default PARTITION OF sales_region DEFAULT;
INSERT INTO sales_region VALUES (6, 9, 'US');
INSERT INTO sales_region VALUES (7, 8, 'AG');
INSERT INTO sales_region VALUES (8, 10, 'IN');
SELECT * FROM sales_region;
SELECT * FROM sales_region_default;
Ref Image:
Hash type partition
In a hash-based partition, we divide large data into multiple tables based on some numeric data like primary key itself. This avoids the concentration of data in a single place and distributes data evenly across partitioned tables.
Example: Split a table into 3 partitions (n is the hash value created from the value in the partition key)
n % 3 = 0 → Allocates to partition 1
n % 3 = 1 → Allocates to partition 2
n % 3 = 2 → Allocates to partition 3
-- hash partition
CREATE TABLE customers (customer_id int, name text, email text) PARTITION BY HASH (customer_id);
CREATE TABLE customers_0 PARTITION OF customers FOR VALUES WITH (MODULUS 3,REMAINDER 0);
CREATE TABLE customers_1 PARTITION OF customers FOR VALUES WITH (MODULUS 3,REMAINDER 1);
CREATE TABLE customers_2 PARTITION OF customers FOR VALUES WITH (MODULUS 3,REMAINDER 2);
INSERT INTO customers VALUES (3, 'kshitij', 'kshitij@lummo.com');
INSERT INTO customers VALUES (7, 'nidhi', 'nidhi@example.com');
INSERT INTO customers VALUES (11, 'coco', 'coco@example.com');
INSERT INTO customers VALUES (2, 'ankit', 'ankit@example.com');
INSERT INTO customers VALUES (9, 'krish', 'krish@example.com');
SELECT * FROM customers;
SELECT * FROM customers_1;
UPDATE customers SET customer_id = 10 WHERE customer_id = 9;
SELECT * FROM customers_1;
Ref Image:
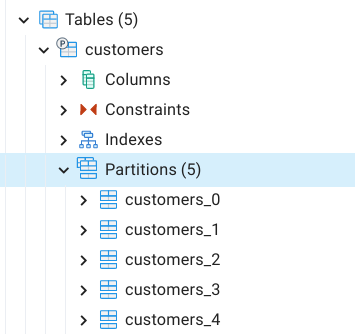
Resizing Hash Partitions
You can increase the number of range partitions and list partitions by specifying a new range and value for the partition key. However, Hash Partitions cannot be added in the same way because the partition is determined by the value of the specified remainder which can change as the number of partitions changes.
In case we want to alter hash partitioning, we have to do the below steps manually:
-- resizing hash partition
-- 1. detaching partitions
ALTER TABLE customers DETACH PARTITION customers_0;
ALTER TABLE customers DETACH PARTITION customers_1;
ALTER TABLE customers DETACH PARTITION customers_2;
-- 2. rename the partitions
ALTER TABLE customers_0 RENAME TO customers_0_bkp;
ALTER TABLE customers_1 RENAME TO customers_1_bkp;
ALTER TABLE customers_2 RENAME TO customers_2_bkp;
-- 3. create new partitions
CREATE TABLE customers_0 PARTITION OF customers FOR VALUES WITH (MODULUS 5,REMAINDER 0);
CREATE TABLE customers_1 PARTITION OF customers FOR VALUES WITH (MODULUS 5,REMAINDER 1);
CREATE TABLE customers_2 PARTITION OF customers FOR VALUES WITH (MODULUS 5,REMAINDER 2);
CREATE TABLE customers_3 PARTITION OF customers FOR VALUES WITH (MODULUS 5,REMAINDER 3);
CREATE TABLE customers_4 PARTITION OF customers FOR VALUES WITH (MODULUS 5,REMAINDER 4);
-- 4. restore data from detached backup partitions
INSERT INTO customers SELECT * FROM customers_0_bkp;
INSERT INTO customers SELECT * FROM customers_1_bkp;
INSERT INTO customers SELECT * FROM customers_2_bkp;
-- 5. delete the detached partitions
DROP TABLE customers_0_bkp;
DROP TABLE customers_1_bkp;
DROP TABLE customers_2_bkp;
SELECT * FROM customers;
SELECT * FROM customers_4;
- We might require to handle indexes and other constraints as well to avoid conflicts in resizing.
It's important to understand that these partitions are logical (however they can have different physical spaces as well). Attaching and detaching just alter logic between table relationships e.g. if we detach a partition, it will become a normal table without any other side effect. DB will just remove its logical relationship with the parent table and we'll be able to access that table just like any other table.
Composite partitioning/ subpartition
In composite partitioning, we have multi-level partitioning of data e.g. in the below example, we are partitioning orders_log based on month-wise partitioning and then we are partitioning month-wise partitions further to hash partitioning on user_id.
One more example we had covered above is list-based partitioning where we could divide orders table time-wise and then order_status based.
One more example we can think of is sensor data logging. In this scenario, we can have list-based partitioning on individual devices, and then we can have range-based partitioning on data. Since our operations would be sensor based, this would be more logical.
The composite partition can go many levels deep.
-- subpartition/ composite partitioning
-- assuming orders_log table where we have frequent access to new orders and user-wise orders
-- approach would be to partition month-wise data and further partition to hash-based partition on user
CREATE TABLE orders_log (id int, user_id int, amount float, created_at date) PARTITION BY RANGE (created_at);
CREATE TABLE orders_log_2022_Jan
PARTITION OF orders_log FOR VALUES FROM ('2022-01-01') TO ('2022-02-01')
PARTITION BY HASH(user_id);
CREATE TABLE orders_log_2022_Feb
PARTITION OF orders_log FOR VALUES FROM ('2022-02-01') TO ('2022-03-01')
PARTITION BY HASH(user_id);
CREATE TABLE orders_log_2022_Jan_0 PARTITION OF orders_log_2022_Jan FOR VALUES WITH (MODULUS 3, REMAINDER 0);
CREATE TABLE orders_log_2022_Jan_1 PARTITION OF orders_log_2022_Jan FOR VALUES WITH (MODULUS 3, REMAINDER 1);
CREATE TABLE orders_log_2022_Jan_2 PARTITION OF orders_log_2022_Jan FOR VALUES WITH (MODULUS 3, REMAINDER 2);
CREATE TABLE orders_log_2022_Feb_0 PARTITION OF orders_log_2022_Feb FOR VALUES WITH (MODULUS 3, REMAINDER 0);
CREATE TABLE orders_log_2022_Feb_1 PARTITION OF orders_log_2022_Feb FOR VALUES WITH (MODULUS 3, REMAINDER 1);
CREATE TABLE orders_log_2022_Feb_2 PARTITION OF orders_log_2022_Feb FOR VALUES WITH (MODULUS 3, REMAINDER 2);
INSERT INTO orders_log VALUES (1, 201, 29.35, '2022-01-15');
INSERT INTO orders_log VALUES (2, 305, 5.25, '2022-02-28');
INSERT INTO orders_log VALUES (3, 111, 50.85, '2022-02-21');
INSERT INTO orders_log VALUES (4, 987, 62.40, '2022-01-11');
INSERT INTO orders_log VALUES (5, 201, 75.00, '2022-02-15');
INSERT INTO orders_log VALUES (6, 333, 42.35, '2022-01-25');
INSERT INTO orders_log VALUES (7, 982, 15.15, '2022-02-26');
INSERT INTO orders_log VALUES (8, 791, 22.00, '2022-01-11');
INSERT INTO orders_log VALUES (9, 456, 91.40, '2022-01-02');
INSERT INTO orders_log VALUES (10, 266, 23.20, '2022-02-18');
SELECT * FROM orders_log;
SELECT * FROM orders_log_2022_Jan;
SELECT * FROM orders_log_2022_Jan_1;
-- get user orders log in january month
SELECT * FROM orders_log WHERE created_at BETWEEN '2022-01-01' AND '2022-02-01' AND user_id=201;
Ref Image:
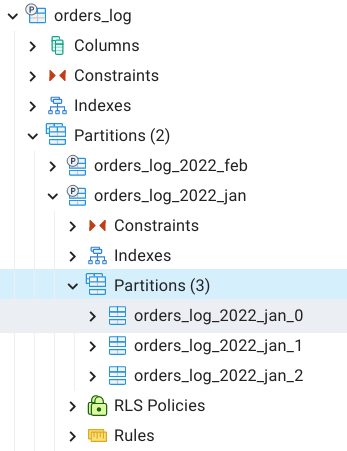
We have the option to use multiple columns to create partitions but it is not covered in this blog yet.
Partition key can be expression as well e.g.
PARTITION BY RANGE (date_trunc('day', created_at))which would create partition based on the day increated_atfield.
Limitations of PostgreSQL Partitions
Here are a few limitations of PostgreSQL Partitions:
A partition key constraint ensures data is distributed efficiently across partitions in a database, typically requiring that unique constraints or primary keys include the partition key column.
There is no option to build indexes or constraints like primary key and unique key globally across all the partitions of a table. Each partition manages its own indexes and constraints which brings down the consistency of the system. There are hacks to fix this but PostgreSQL doesn't provide anything out-of-the-box to manage this.
Foreign keys referencing partitioned tables, as well as foreign key references from a partitioned table to another table, are not supported because primary keys are not supported on partitioned tables.
Row triggers must be defined on individual partitions and not in the partitioned table.
Range partitions do not accept NULL values.
JOIN queries can take a hit on performance due to cross-table access.
Since partition tables should be created manually, we should add a scheduler/ cron to create those beforehand. We can create a partition function that can just take parameters to create tables dynamically. We can define partition-wise indexes and constraints in the same function for each partition table.
I hope this blog would have given you a basic understanding of PostgreSQL partitioning. Try the queries in the blog and try playing with them with different variations around strengths and weaknesses.